Technical Overview
The DPRR web application offers fine-grained data about the elite of the Roman Republic, allowing the detailed study of its attested individuals, including familial composition, office-holding patterns, internal hierarchies, property and wealth.
The project was developed to allow users easy access to complex data and enable them to answer questions such as:
- list the individuals who were praetors between 200-100 BCE with nomen Caecilius;
- list proconsuls in Gallia between 100-80 BCE;
- show all persons who were both consul and pontifex between 123 and 100 BCE (i.e. consuls who were also pontifices);
- visualise the composition of the senate in the year 100 BCE;
- show all persons with a birth date and a death date between 250-100 BCE;
- list all women that died of violent death.
To preserve the richness of the data, while allowing research questions like these to be answered, the DPRR data model was designed to store the prosopographical data in structured form. This model was built upon previous experience acquired developing similar projects, which are also currently maintained by King’s Digital Lab (KDL):
- Prosopography of the Byzantine Empire
- Clergy of Anglo-Saxon England Database
- Prosopography of Anglo-Saxon England
- Prosopography of the Byzantine World
- People of Medieval Scotland
- Making of Charlemagne’s Europe
The technical team had originally expected to follow the factoid prosopography model quite closely (see https://factoid-dighum.kcl.ac.uk/), as it had been developed at KCL and applied to the other structured prosopographies mentioned above. Although some of the ideas from the factoid model are still found in DPRR's structure, since it generates its prosopographical data from 19th, 20th and 21st century secondary sources, rather than primary ones, DPRR operates data model is significantly different from these other prosopographies.
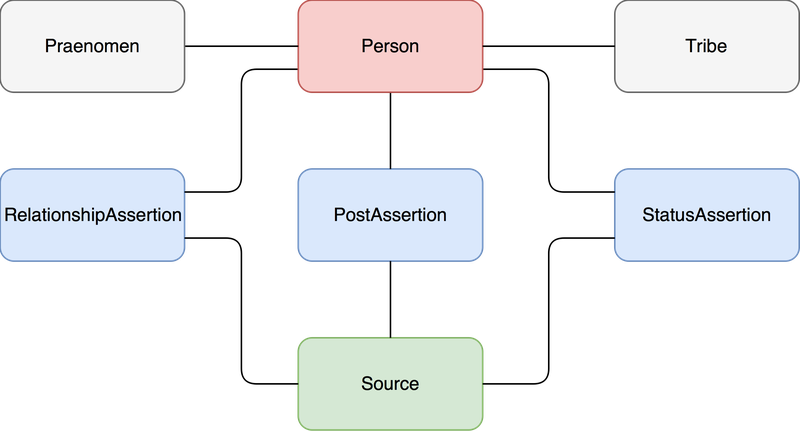
The data model is organised around four main entities: Person, PostAssertion, StatusAssertion and RelationshipAssertion. The main entity, Person, stores information about each individual, such as names, gender, life dates, patrician indicator, etc. The PostAssertion entity stores data related to offices/posts held by individuals (such as praetor, consul, legate, etc), while the StatusAssertion stores senatorial and equestrian class information. The RelationshipAssertion represents personal relationships (brother of, son of, etc), connecting two different individuals within the database. All these entities are linked, as represented in the figure below. All Assertion models are linked to a SecondarySource entity with details about the bibliographical references supporting the data.
The data for the project has been harvested from multiple sources – mainly from Broughton's Magistrates of the Roman Republic (1951-86), Ruepke's Fasti Sacerdotum (2005) and Zmeskal's Adfinitas (2009). The data was automatically loaded using scripts developed for each source (see figure below for the data workflow). A data editing interface was also developed and mostly used to make corrections to the automatically loaded data, as well as adding new information when needed.
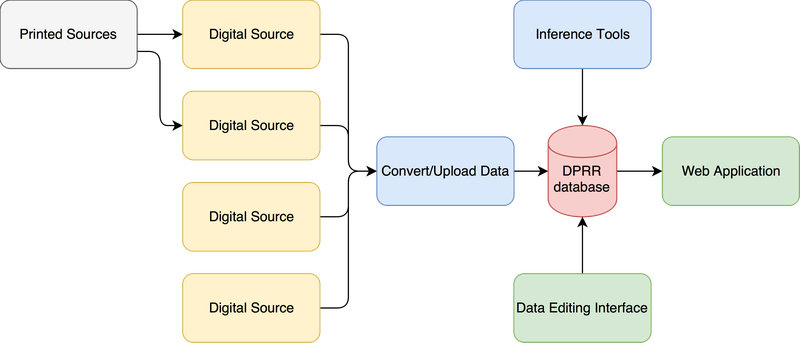
Besides loading and entering data directly into the database, the web application also has rules to infer new information about personal relationships and senators. As an example of the senator rules, the application creates a Senator object for a person that held a specific post in a given year that would make them senators ex-officio; such as consul, praetor, aedile, tribunus plebis, censor, princeps senatus.
The database, which stores all this information in an easily searchable format, is displayed by a web application. The website allows the public to explore the data using a faceted search interface. Different filters can be applied, guiding users to answers to the research questions above. By selecting individual results, it is possible to see all the information about a person, including their career and personal relationships. In addition to providing a browser-oriented search engine for DPRR data, DPRR has also published its data using Semantic Web and Linked Open Data principles. The LOD/RDF data was extracted from the created database and loaded into the DPRR RDF server to provide RDF endpoint for the project data. The process, enabled by KDL, was conceived and implemented by the DPRR co-investigator John Bradley.
The project is built using open source tools and technologies, primarily the Django application framework with a PostgreSQL database. The search interface is implemented using the Solr search engine together with the django-haystack package for Django. The user interface has been designed using Django HTML templates, CSS and JavaScript, building on top of the Foundation Zurb framework. The project and the RDF server source code are both available in GitHub.
This technical overview is based on the poster by Luis Figueira and Miguel Vieira, presented at the Digital Humanities 2017 conference.
References
- Bradley, J. and Short, H. (2002) Using Formal Structures to Create Complex Relationships: The Prosopography of the Byzantine Empire A Case Study. In K. S. B. Keats-Rohan (ed) Resourcing Sources. The Use of Computers in Developing Prosopographical Methodology, Oxford: Occasional Publications of the Unit for Prosopographical Research, Linacre College, Oxford.
- Pasin, M. and Bradley, J (2013) Factoid-based prosopography and computer ontologies: towards an integrated approach. Literary and Linguistic Computing, Volume 30, Issue 1, 1 April 2015, Pages 86–97.